
Audit Log로 데이터 웨어하우스 가드레일 만들기
운영 데이터베이스를 GCP DataStream으로 ODS에 스트리밍하다 보면, “스트리밍만 잘 되면 끝”이라고 생각하기 쉽습니다. 하지만 실제 운영에서는 데이터 적재보다 적재 이후의 관리가 더 어렵습니다.
저희도 비슷한 문제를 겪었습니다. 운영 DB에 기본값이 있는 컬럼이 추가되었는데, 이 값이 BigQuery 쪽에서는 null로 들어가는 이슈가 있었습니다. 결국 잘못 적재된 데이터를 지우고 다시 채워 넣는 backfill 작업이 필요했습니다.
문제는 여기서 끝나지 않았습니다. 개인 정보가 포함된 컬럼에 대해 Dynamic Data Masking 같은 DDM 처리가 누락되면, 테이블 재생성이나 교체 과정에서 민감 정보가 그대로 노출될 수 있는 위험도 있었습니다.
이 글은 이런 운영 리스크를 줄이기 위해 audit log를 활용해 데이터 웨어하우스 관리 파이프라인을 구성했던 경험을 정리한 글입니다.
아키텍처 한눈에 보기
첨부했던 구성을 글 안에서도 다시 보면 아래와 같은 흐름입니다.
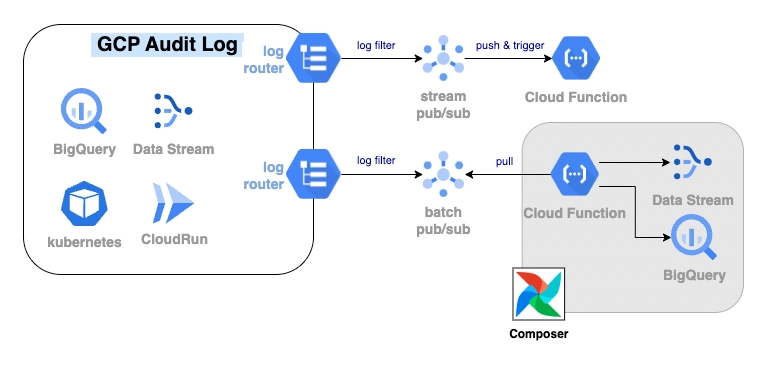
핵심은 Audit Log를 중심으로 이벤트를 수집하고, 성격에 따라 stream 처리와 batch 처리 경로를 분리한 점입니다.
문제는 적재가 아니라 변경에서 시작되었습니다
스트리밍 파이프라인은 보통 “새 데이터가 잘 들어오는가”에 초점을 맞춥니다. 하지만 실제 운영 환경에서는 아래와 같은 변경 이벤트가 더 위험합니다.
- 운영 DB 스키마 변경
- 기본값이 있는 컬럼 추가
- BigQuery 테이블 재생성
- PII 컬럼이 포함된 테이블 생성 또는 교체
특히 운영 DB에 기본값이 지정된 컬럼이 추가될 때, Data Stream이 이를 BigQuery에 정확히 반영하지 못해 기본값 대신 null이 적재되는 문제가 있었습니다. 이건 단순 적재 오류가 아니라, downstream 분석 결과를 왜곡시키는 데이터 정확성 이슈였습니다.
또 다른 문제는 보안이었습니다. 원래 PII 컬럼은 DDM 처리를 통해 특정 권한을 가진 사용자만 원문에 접근 가능하도록 관리하고 있었는데, 테이블 유지보수 과정에서 새로 만들어진 테이블에 이 처리가 자동으로 적용되지 않으면 정책이 깨질 수 있었습니다.
데이터 엔지니어 관점에서 보면, 둘 다 공통점이 있습니다. 데이터 파이프라인 자체보다 “메타데이터와 변경 이벤트를 감시하는 시스템”이 없어서 생긴 문제라는 점입니다.
Audit Log를 데이터 웨어하우스 운영 이벤트 소스로 사용했습니다
이 문제를 풀기 위해 저희는 Google Cloud Audit Logs를 단순 감사 용도가 아니라, 운영 이벤트를 감지하는 트리거 소스로 활용했습니다.
Audit Log는 Google Cloud 리소스에서 어떤 동작이 일어났는지를 기록합니다. 누가 언제 어떤 테이블을 만들었는지, 어떤 서비스가 어떤 변경을 발생시켰는지 같은 정보가 남습니다.
이 로그를 잘 쓰면 데이터 자체를 읽지 않고도 아래 같은 운영 이벤트를 감지할 수 있습니다.
- BigQuery 테이블 생성
- 스키마 변경
- 특정 서비스 계정이 수행한 관리 작업
- 예상하지 못한 테이블 교체나 삭제
이 방식의 장점은 명확합니다. 데이터 품질이나 보안 정책을 “사후 점검”이 아니라 “이벤트 기반 대응”으로 바꿀 수 있다는 점입니다.
파이프라인은 Stream과 Batch로 나눴습니다
모든 이벤트를 같은 방식으로 처리하지는 않았습니다. 어떤 작업은 즉시 반응해야 했고, 어떤 작업은 일정 시간 모아서 처리하는 편이 안전했습니다. 그래서 audit log 파이프라인을 Stream 처리와 Batch 처리로 나눴습니다.
1. Stream 처리: BigQuery 테이블 생성 시점 대응
즉시 대응이 필요한 대표 사례는 BigQuery 테이블 생성 이벤트였습니다.
PII가 포함된 테이블은 생성 직후 DDM 처리가 적용되어야 합니다. 만약 운영 중 테이블을 재생성했는데 DDM이 누락되면, 짧은 시간이라도 원본 데이터가 그대로 노출될 수 있습니다.
그래서 테이블 생성 audit log를 실시간으로 받아, 대상 테이블인지 판별한 뒤 필요한 DDM 정책을 자동 적용하는 흐름을 구성했습니다.
흐름을 단순화하면 아래와 같습니다.
- Audit log가 테이블 생성 이벤트를 기록합니다.
- Log Router가 해당 이벤트를 Pub/Sub로 전달합니다.
- Stream 처리 파이프라인이 이벤트를 읽습니다.
- 생성된 테이블이 PII 대상인지 판별합니다.
- 대상이면 DDM 정책을 자동 적용합니다.
이 구조의 핵심은 “정책 적용을 사람이 기억하는 작업에서 시스템이 보장하는 작업으로 바꾼 것”입니다.
예를 들어 Cloud Function 쪽의 개념적인 코드는 아래처럼 단순화할 수 있습니다.
import base64
import json
def handle_bq_table_created(event, context):
payload = json.loads(base64.b64decode(event["data"]).decode("utf-8"))
resource_name = payload["protoPayload"]["resourceName"]
if not is_pii_table(resource_name):
return
apply_dynamic_data_masking(resource_name)
def is_pii_table(resource_name: str) -> bool:
pii_keywords = ["user", "member", "customer", "phone", "email"]
return any(keyword in resource_name.lower() for keyword in pii_keywords)
def apply_dynamic_data_masking(resource_name: str):
# 실제 구현에서는 BigQuery Policy Tag 또는 DDM 정책을 연결합니다.
print(f"Apply DDM policy to {resource_name}")
실제 운영 코드에서는 테이블명 패턴만 보는 것이 아니라, 메타데이터 레지스트리나 사전 정의한 PII 대상 목록을 기준으로 판별하는 편이 더 안전합니다.
2. Batch 처리: Data Stream 스키마 변경 대응
반대로 운영 DB 스키마 변경은 일괄 처리 쪽이 더 적합했습니다.
기본값이 있는 컬럼이 추가된 경우에는 아래 절차가 필요했습니다.
- 로그를 읽고 스키마 변경 이벤트인지 확인합니다.
- 변경 유형이
add column인지 확인합니다. - 추가된 컬럼이 기본값을 가지는지 확인합니다.
- 영향 테이블을 drop 합니다.
- Data Stream에 backfill을 요청합니다.
문제는 이 과정이 가볍지 않다는 점입니다. 테이블이 크면 backfill만 수 분에서 1시간 정도 걸릴 수 있었고, max_staleness 설정 때문에 backfill 직후에도 바로 조회되지 않고 최대 15분 정도 대기 시간이 발생할 수 있었습니다.
그래서 이 작업은 사용자가 거의 접근하지 않는 시간대인 매일 23시에 일괄 수행하도록 설계했습니다. 즉, 실시간 감지와 지연 실행을 분리한 것입니다.
데이터 엔지니어링에서는 “빨리 처리하는 것”보다 “운영 충격을 줄이는 것”이 더 중요할 때가 많습니다. 이 경우가 정확히 그랬습니다.
이 로직의 포인트는 “모든 스키마 변경을 복구 대상으로 보지 않는다”는 점입니다. 실제 운영에서는 영향 범위가 큰 케이스만 자동 조치 대상으로 좁혀야 합니다.
실제 구성 요소는 비교적 단순했습니다
구성 자체는 아주 복잡하지 않았습니다.
- Log Router
- Pub/Sub
- Composer DAG
- Batch Manager
- Data Stream
배치 플로우 기준으로 보면, Log Router가 특정 audit log를 audit-log-pubsub-batch 토픽으로 보내고, Composer의 monitoring_internal_farmmorning DAG 안에 있는 task_check_audit_log_pubsub 작업이 이를 확인한 뒤, 별도 Batch Manager 코드를 통해 실제 점검 및 backfill 로직을 수행하는 구조였습니다.
이런 구성에서 중요한 것은 서비스 수가 아니라 책임 분리입니다.
- 로그 라우터는 이벤트를 분류합니다.
- Pub/Sub는 이벤트를 전달합니다.
- Composer는 스케줄과 오케스트레이션을 담당합니다.
- Batch Manager는 도메인 로직을 수행합니다.
- Data Stream은 실제 재적재를 담당합니다.
책임이 분리되면 장애 분석도 쉬워집니다. 이벤트가 안 들어왔는지, 스케줄이 안 돌았는지, 분기 로직이 틀렸는지, backfill 요청이 실패했는지를 단계별로 확인할 수 있기 때문입니다.
이 설계에서 가장 중요했던 것은 데이터보다 메타데이터였습니다
처음에는 “스트리밍 데이터 문제를 어떻게 해결할까”로 출발했지만, 실제로는 데이터를 직접 읽는 로직보다 메타데이터와 운영 로그를 다루는 로직이 더 중요했습니다.
예를 들어 여기서 본질적인 질문은 아래와 같았습니다.
- 어떤 테이블이 PII 대상인가
- 어떤 스키마 변경이 위험한가
- 어떤 이벤트는 즉시 처리해야 하는가
- 어떤 작업은 야간 배치로 미뤄야 하는가
- 언제 사람 개입 없이 자동 조치해도 안전한가
이 질문들에 답하기 위해서는 원본 데이터보다 리소스 변경 이력과 정책 정보가 더 중요했습니다.
데이터 엔지니어 관점에서 보면, 안정적인 데이터 플랫폼은 결국 “데이터 파이프라인”과 “운영 제어 파이프라인”이 같이 있어야 합니다. 적재 파이프라인만 있고 감시 체계가 없으면, 문제는 늦게 발견되고 복구 비용은 커집니다.
얻은 교훈
이 작업을 하면서 얻은 교훈은 크게 세 가지였습니다.
1. 데이터 품질 이슈는 보통 스키마 변경에서 시작됩니다
데이터가 깨지는 가장 위험한 순간은 대개 신규 적재보다 변경 이벤트입니다. 컬럼 추가, 타입 변경, 기본값 설정, 테이블 교체 같은 변화는 작은 이벤트처럼 보이지만 downstream 전체를 흔들 수 있습니다.
2. 보안 정책은 수동 절차로 두면 반드시 빠집니다
PII 처리나 DDM 적용이 문서나 체크리스트에만 의존하면, 언젠가는 누락됩니다. 사람이 실수하지 않는 시스템을 기대하기보다, 시스템이 사람 실수를 흡수하도록 만들어야 합니다.
3. Audit Log는 감사 기록이 아니라 운영 자동화의 입력값이 될 수 있습니다
많은 팀이 audit log를 보안 감사나 사후 분석 용도로만 봅니다. 하지만 실제로는 운영 이벤트를 감지하고 후속 조치를 트리거하는 아주 강력한 입력 채널이 될 수 있습니다.
마무리
이 파이프라인의 목적은 단순히 로그를 쌓는 것이 아니었습니다. 데이터 웨어하우스에서 발생하는 활동을 추적하고, 데이터 정확성을 유지하고, 개인 정보 유출 가능성을 줄이는 운영 가드레일을 만드는 것이 목적이었습니다.
개인적으로는 이런 종류의 작업이 데이터 엔지니어링의 본질에 더 가깝다고 생각합니다. 데이터를 잘 적재하는 것도 중요하지만, 변경과 예외를 통제하고 안전하게 복구 가능한 시스템을 만드는 것이 결국 플랫폼 신뢰도를 결정하기 때문입니다.
스트리밍 파이프라인을 운영하고 있다면, 이제는 “데이터가 들어오고 있는가”만 볼 것이 아니라 “무슨 변경이 일어났는가”도 함께 봐야 한다고 생각합니다. Audit Log는 그 출발점으로 꽤 좋은 도구였습니다.
댓글 남기기
댓글 목록
관리자 보기